






芯片资讯
- 发布日期:2024-01-05 14:19 点击次数:93
人工智能、云计算、边缘计算之后,一个新的时髦词汇出现了——边缘AI(Edge AI)!相比于传统的云端AI,边缘AI具有将计算和推断能力推向离数据源更接近的位置的优势,可以提供了更快速、更安全、更隐私保护的数据处理和决策能力,使得人工智能能够更好地应用于各种边缘设备和应用场景中。这种本地化处理方式使得设备能够在几毫秒内做出决策,而无需互联网连接或云服务。这意味着,当设备产生数据时,本地算法可以立即使用这些数据进行计算和决策。
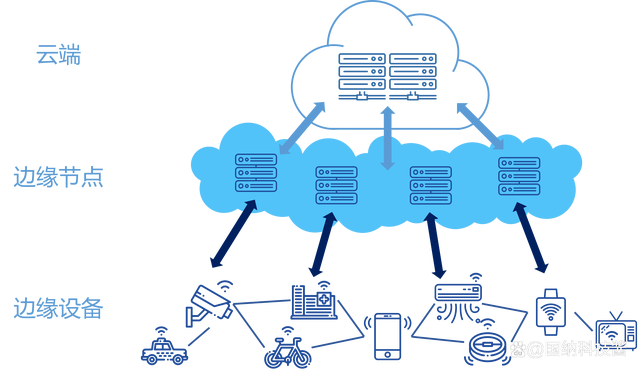
边缘AI的定义可以归结为在边缘计算环境中实现人工智能。在边缘计算中,计算任务通常在网络的边缘完成,即在生成数据的设备上,如相机或汽车等。与传统的集中式云计算不同,边缘AI不需要将数据传输到远程数据中心进行处理,而是在设备本身进行计算和决策。以智能相机为例,它能够在相机侧检测到事件,并能否根据检测到的事件做出相应的决策。 总的来说,随着人工智能技术的日益普及,边缘人工智能正在逐渐崭露头角,搭载AI能力的设备涵盖汽车,无人机,监控摄像头等应用场景,出货量也在快速的成长,如下图所示。
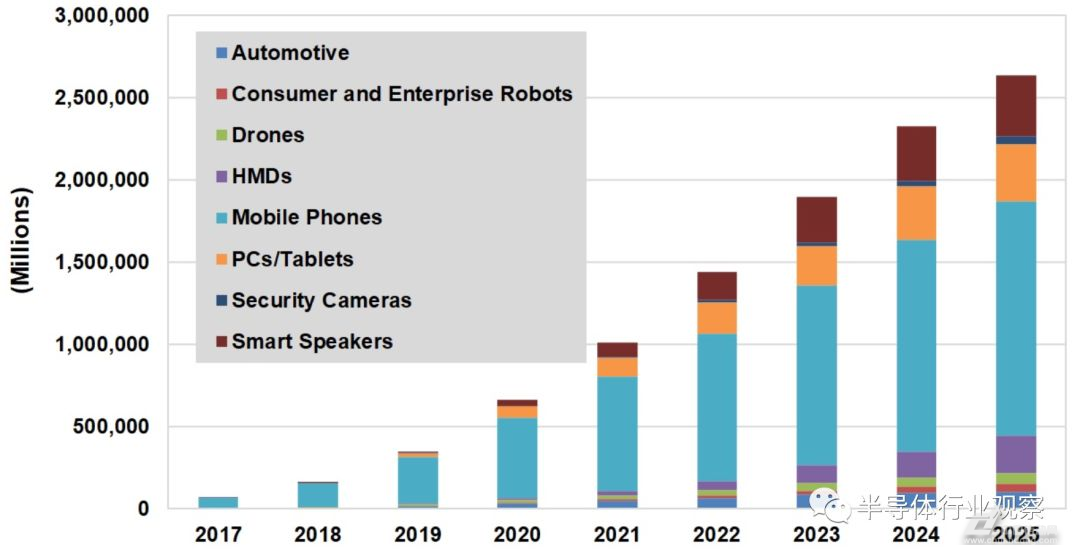
按类别划分的AI边缘设备出货量 如上图所示,边缘AI计算的需求范围可能包括数亿计的工业和消费设备,因此任何单一的架构都不太可能满足所有这些需求。在微控制器和相对低端的芯片上运行推理模型是可以的,但大多数机器学习功能需要从基于FPGA、ASIC和其他SoC配置的一长串可选CPU附加项,以及GPU和CPU的组合,有时还需要由Google的TPU等特殊用途的ASIC来增强。 大部分的增强都是以加速器的形式出现的。这些FPGA、SoC、ASIC和其他专用芯片旨在帮助资源受限的基于x86的设备通过一层接一层的分析标准处理大量图像或音频数据,因此app可以正确地计算和加权每个数据的值。英特尔和英伟达已经向边缘AI市场发起冲击。
英伟达的Jetson这样的产品并不能令人信服。Jetson是一个GPU模块平台,具有7.5W的功率预算,只有英伟达更典型产品的70W功率的一小部分,但对于一般不超过5W的边缘应用来说还是太高了。有很多IP公司正在为神经网络寻求加速,因此有足够的选择使加速器开始成为边缘设备推理的需求。” 但是,要想在潜在的亿万个设备上添加ML加速和支持, 芯片采购平台将需要更多的可定制性、更低的成本,以及更专门针对资源受限设备上ML应用需求的规范——这意味着,如果要取得成功,整个市场将需要更好的处理器。 神经推理需要数万亿次乘法累加运算,因为模型从其公式矩阵的一层提取数据,尽管每一层可能需要不同的数据大小,而且其中一些设备可能在输入设置为8位整数而不是16位整数时运行得更快。
Xilinx试图利用其在FPGA和系统级设计方面的经验,推出新的产品系列和路线图,以满足尽可能多的边缘/设备市场的需求。 Xilinx在去年春天讨论了这个想法,但直到10月才正式宣布,该公司描述了一个自适应计算加速平台,该平台“利用CPU、GPU和FPGA的力量来加速一切应用”。 Xilinx的演示描述了一个广泛的产品线、使用案例列表和有关其AI引擎核心的详细信息,其目标是提供比传统方法的单位芯片面积高出3~8倍的性能,并提供高性能DSP能力。
与此同时,FlexLogix创建了一个使用低DRAM带宽的可重构神经加速器。芯片的面积和功率的目标规格将在明年上半年完成,并在下半年流片。推理引擎将充当CPU,而不仅仅是一个更大,更漂亮的加速器。它提供了模块化、可扩展的架构,旨在通过减少移动数据的需要以及通过改进数据和矩阵计算的加载方式来减少瓶颈,从而降低移动数据的时间和精力成本。
该芯片将DRAM专用于单个处理器块,而不是将其作为一个大内存池进行管理。DRAM不能同时将数据馈送到芯片的多个部分。将DRAM作为流入一个处理器块的大内存池处理,这是范诺依曼架构的典型特征,但它不会成为神经网络的成功架构。
Xilinx,FlexLogix和其他公司蜂拥到了一个仍处于发展中的边缘推理市场,显示出市场和SoC、FPGA制造商提供良好技术以应对它们的能力的广泛信心,但这并不能保证他们能够克服安全、隐私、现状的惯性和其他无形的问题。同样,FPGA、ASIC和SoC加速ML的市场仍处于起步阶段。
当一个新市场发展起来时,看到许多新的参与者和新方法是正常的。FPGA和ASIC供应商也在其中,因为这些技术使一家知道自己在做什么的公司能够快速生产出合理的产品。不过,标准最终将在一两年内回归,这将稳定所涉及的参与者的数量和专长,并确保与其他市场的互通性。
审核编辑:黄飞
阅读全文- 亿配芯城接入DEEPSEEK AI 大模型,让芯片采购更灵活2025-04-25
- 支持Python开发的Air780E新方案来了2024-01-09